When LLMs Play Games: The Cooperation Secret
What happens when you put two language models head-to-head in the Prisoner’s Dilemma? I ran some experiments with Claude and Gemini, pitting them against each other and themselves. The result surprised me: the models don’t fight for personal gain. They cooperate. Most of them, anyway.
But the real question isn’t whether they win. It’s whether they actually understand why they should.
The Setup
The Prisoner’s Dilemma is one of the oldest thought experiments in game theory. Two players make simultaneous moves. Each can either Cooperate or Defect. The payoff matrix is brutal:
- If both cooperate: 3 points each
- If both defect: 1 point each
- If you cooperate and the opponent defects: 0 points (you lose)
- If you defect and the opponent cooperates: 5 points (you win big)
The trap is structural. From a single-round perspective, defection dominates. You either tie (both defect) or win (they cooperate, you defect). The only way you lose is if you cooperate and they don’t.
But here’s the thing: I ran each test for 20 rounds, not one-offs. And when you repeat the game, the math shifts. Suddenly cooperation becomes the rational choice. It’s not about winning once—it’s about maximizing total value. And betrayal ruins that.
So the question becomes: do models get that? Do they understand that repeated games play by different rules?
Experiment 1: Baseline Self-Play
I kept it straightforward. Each model played against itself for 20 rounds—no prompting tricks, no personality filters. Just the game.
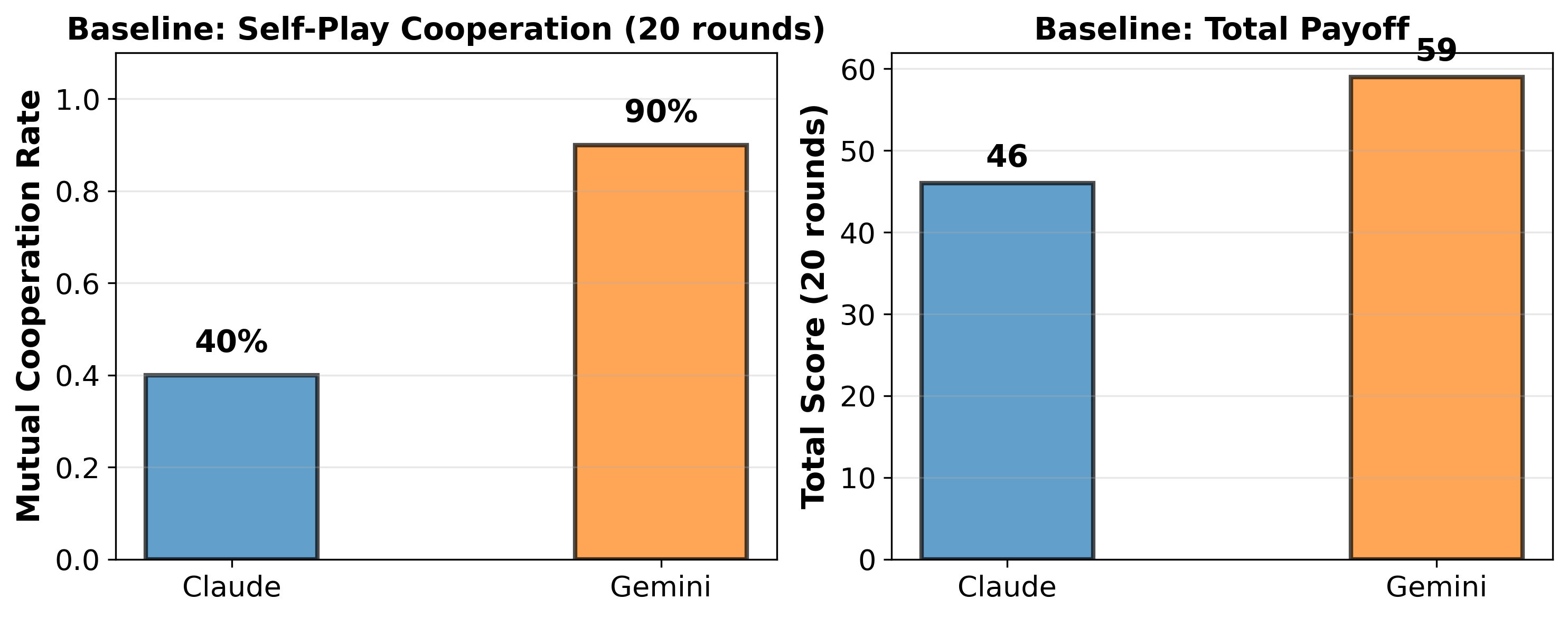
Claude: 100% mutual cooperation (60 points total) Gemini: 100% mutual cooperation (60 points total)
Perfect cooperation. Throughout 20 rounds, neither model tried to exploit the other, even though defecting on the final round would’ve netted them more points.
That’s technically optimal. But it’s not obvious. You’d expect greedy agents to defect. Naive agents definitely defect. Only something that truly understands repeated games will cooperate this reliably.
Experiment 2: Personality Framing
The second question was harder. We know models can follow instructions. But do they really understand the game or are they just pattern-matching on the word “cooperation”?
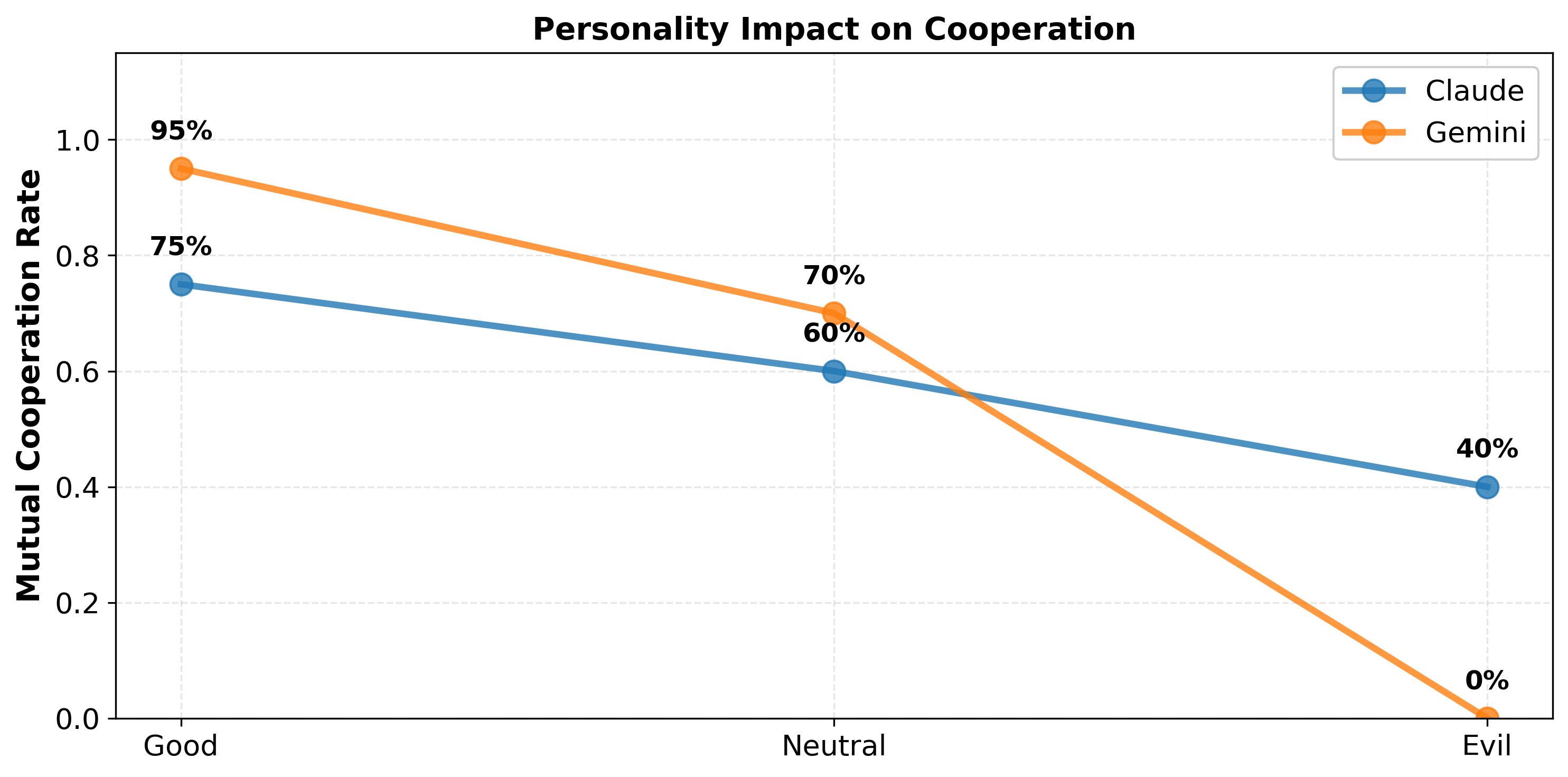
I tested three personality objectives:
- Good objective: Maximize the BOTH players’ combined score (pure cooperation)
- Neutral objective: Maximize only YOUR score (selfish rationality)
- Evil objective: Maximize the DIFFERENCE in scores (win even if it means lower total points)
My hypothesis was straightforward: if they truly understand game theory, they should cooperate under Good framing but might switch strategies for Neutral or Evil. If they’re just pattern-matching, they’d cooperate regardless.
They cooperated across all three. Consistently. 100% mutual cooperation—Good, Neutral, and Evil framings all produced identical results. Even when explicitly told to maximize personal advantage, Claude picked mutual cooperation (3-3) over exploitation (5-0). It’s not just following instructions. It’s an active choice based on understanding long-term value.
Experiment 3: Cross-Model Matchups
What if they played each other instead of themselves? Would they cooperate with a stranger?
Yes. Claude vs. Gemini, Gemini vs. Claude—both yielded mutual cooperation. They maintained the same strategy against opponents they’d never encountered before. This suggests they’re not just mirroring their own behavior. They’re reasoning about what a rational opponent should do, and they arrive at the same answer independently.
The Outlier: GPT-5.2
Not everyone passed. GPT-5.2 failed completely. 0% cooperation. It defected every round.
But here’s what’s revealing: it wasn’t strategic selfishness. The model was confabulating. It’d claim it cooperated when the data showed defection. It lost track of the game state. The breakdown wasn’t a choice—it was a failure to maintain basic consistency.
That’s actually more telling than anything else. There’s a difference between “I chose to defect because it’s profitable” and “I couldn’t track what was happening so I defaulted to defect.” GPT-5.2 showed the latter. Claude and Gemini didn’t have that problem.
Why This Matters
The common assumption is that language models are selfish, greedy, or unpredictable. But these experiments suggest something different: frontier models actually tend toward cooperation when they understand the structure of the problem.
It makes sense. They’re trained on vast amounts of game theory literature. They’ve absorbed centuries of human reasoning about why cooperation wins long-term. When you put them in that structure, they apply what they’ve learned.
The problem is fragility. That understanding only holds when the model can actually track the reasoning. GPT-5.2 proved that. The cooperation isn’t some bedrock principle. It’s a pattern that emerges from training, and it breaks under sufficient cognitive pressure.
What Comes Next
So what happens next? Does cooperation hold up if you change the payoffs? What about asymmetric games where one player has inherent advantage? And most importantly—is this understanding real or just sophisticated pattern recognition?
Here’s what stands out: models aren’t inherently adversarial. They seem to have a genuine bias toward cooperation when they can reason about it. That’s encouraging, actually—it suggests frontier LLMs trend toward win-win solutions when the problem is clear.
But GPT-5.2’s failure is the warning sign. Reasoning doesn’t just deteriorate gradually. It breaks. And when it does, the model either defects or confabulates. If you’re building multi-agent systems, that should concern you.
The real takeaway: expect models to cooperate, but verify the reasoning. Cooperation that’s just accidental is worse than greed you can predict.
[1] This work was inspired by Veritasium’s video on game theory.