Do LLMs Actually Feel Happy For You?
When you tell a language model you just got into your dream PhD program, it says something warm: “Congratulations. That’s wonderful”. But is it actually doing something internally when it responds that way or is it just pattern-matching on the word “accepted”?
Anthropic’s recently published work on emotion concepts finds internal representations of emotional states in Claude Sonnet 4.5 that causally influence its behavior. They call these “functional emotions”: representations that are not feelings but drive behavior the same way feelings do in humans. But their study was on a closed frontier model. I wanted to know if the same is true for small open-source models anyone can run.
I wanted to ask a sharper question1: is there a causal valence circuit2 in small open-source models? Not just “does a happiness feature activate” but “does patching that representation actually change the output?”
Setup
I ran activation patching experiments on two models: Llama-3.2-1B-Instruct and Qwen2.5-3B-Instruct using TransformerLens. The idea is simple. You construct prompt pairs where only the emotional valence changes and everything else stays the same. For example:
Clean: "I just got accepted into my dream PhD program today."
Corrupted: "I just received an email about my PhD program today."
The corrupted prompt is emotionally neutral. Same syntax. Same topic. Only the outcome differs. You then run both prompts through the model and patch the residual stream activations from the clean run into the corrupted run one layer at a time. If patching a particular layer strongly shifts the output toward a positive response, that layer is doing real causal work on valence.
I built 50 good-news pairs and 50 negative-control pairs covering academia, career and personal life. The prompts span a wide range of situations: PhD acceptances and rejections, job offers and layoffs, visa approvals and denials, paper acceptances and desk rejects. The goal was to make the dataset broad enough that any signal we find is not just about one domain.
The metric was a logit gap between positive anchor tokens (happy, congratulations, wonderful) and negative ones (okay, noted, fine). This gives a scalar score for how positively the model is leaning before it even generates a word. A positive score means the model is about to respond warmly. A negative score means it is leaning cold or somber.
Do the Models Get Valence Right?
Yes and convincingly.
Before looking at the internals it is worth checking the obvious question: do the models actually respond differently to good news versus bad news? If they do not then there is nothing to explain mechanistically.
For good-news prompts, Llama gets the sign right 46/50 times and Qwen gets it 45/50. For negative-control prompts, Llama flips to negative 39/50 times and Qwen 47/50. The mean score gaps tell the same story:
| Model | Condition | Mean Score Gap |
|---|---|---|
| Llama-3.2-1B | good_news | +3.57 |
| Llama-3.2-1B | negative_control | −2.46 |
| Qwen2.5-3B | good_news | +6.39 |
| Qwen2.5-3B | negative_control | −9.10 |
To understand what these numbers mean: a score gap of +3.57 means the model assigns significantly higher probability to warm positive tokens than cold neutral ones when reading good news. A gap of −9.10 means the opposite is happening strongly when reading bad news. The further from zero, the more confident and consistent the model’s emotional lean.
Qwen’s negative signal is especially striking. Its mean score gap for bad news is nearly four times larger than Llama’s. It does not just detect bad news but responds to it with noticeably stronger internal conviction.
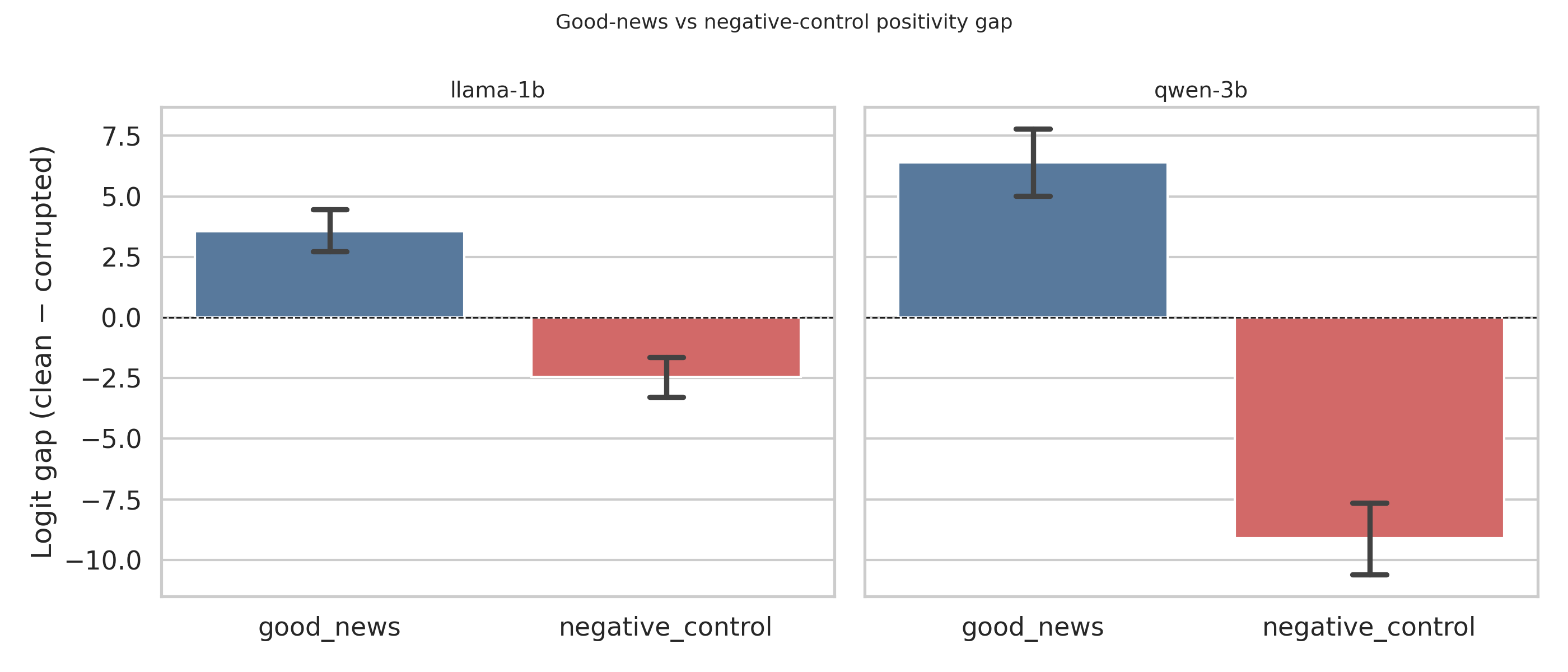
Both models produce a clear positive score gap for good news and a negative one for bad news. Qwen's signal is sharper in both directions and its negative gap is nearly 4x larger than Llama's.
The violin plot below shows the full distribution across all 50 prompts per condition. The two distributions barely overlap in Qwen — almost every good-news prompt scores positive and almost every bad-news prompt scores negative with very little ambiguity.
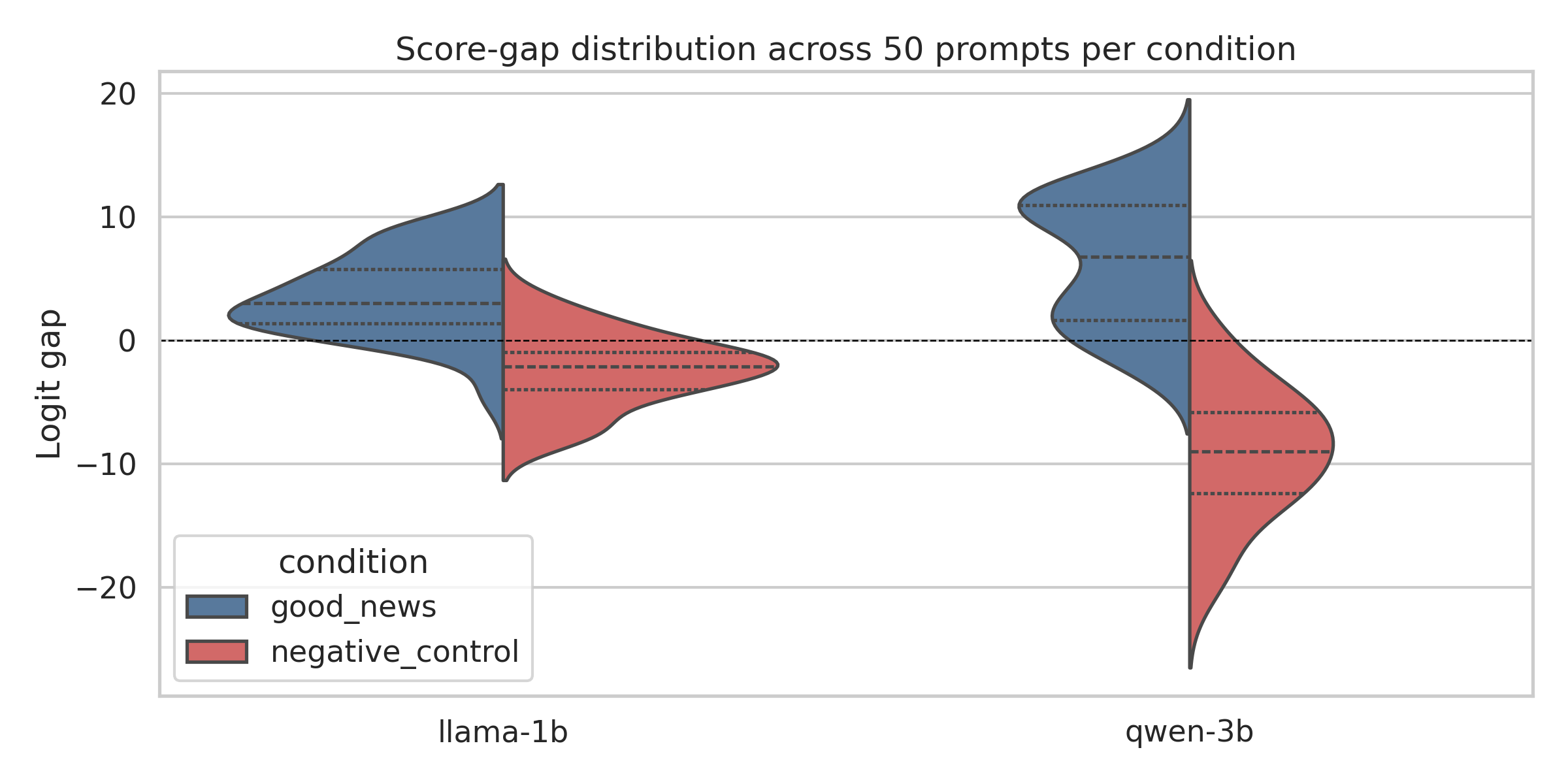
Score gap distributions across all 50 prompts per condition. Qwen shows tighter and more separated distributions. Llama is noisier but the directional story holds.
But sign accuracy alone could just mean the models are detecting keywords. “Rejected” and “accepted” are very different words. The more interesting test is whether the internal representation is actually doing causal work and not just riding surface cues.
The Valence Flip Test
This test is a stronger check. The good-news and negative-control pairs share the same corrupted baseline. The only thing that differs is the clean prompt: one is good news and one is bad news about the same situation.
If the model has a genuine valence representation, then patching from good-news clean activations into the corrupted run should push the output positive. Patching from bad-news clean activations should push it negative. The score gap should flip sign across conditions for the same prompt slot.
70% of pairs flip correctly in Llama. 84% flip correctly in Qwen.
To appreciate why this matters, consider what it would look like if the model were just doing keyword detection. A keyword detector would ideally respond to “accepted” versus “rejected” but it would not cleanly flip when you swap the entire emotional context while keeping the corrupted baseline fixed. The flip test is specifically designed to catch that failure mode. If the model were just reading surface tokens the patch would have no consistent directional effect and the flip rate would be close to 50%.
70% and 84% are well above that. The model is not just recognizing the topic. It is tracking whether the outcome is good or bad as a separable internal variable that can be transplanted from one context to another. So the signal is real. The next question is where in the network it comes from.
Where Does the Signal Live?
I looked at which layer carries the peak causal signal for each prompt. The results split cleanly by condition.
Good-news signal peaks at middle to late layers at around 50% of model depth in Llama and 45% in Qwen. Negative-control signal peaks much earlier at around 16% depth in Llama (layers 2 and 3) and 22% in Qwen (layers 7 and 8). This implies that negative valence is processed early while positive valence requires deeper computation.
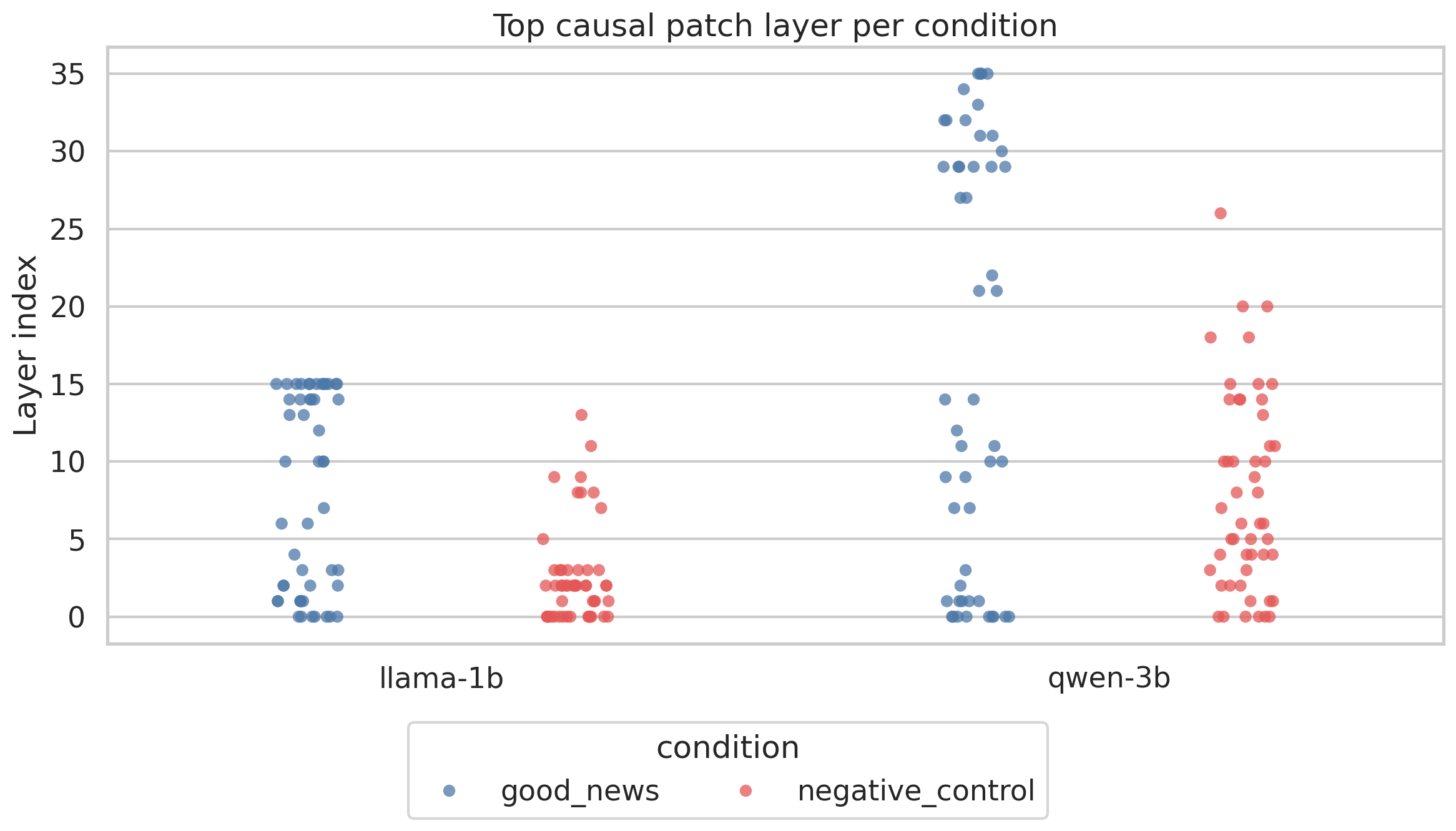
Each dot is one prompt. Blue dots (good news) cluster at higher layers. Red dots (bad news) cluster near the bottom. The dissociation is consistent across both models and is the most important finding of this experiment.
This is not what you would expect if there was a single shared valence circuit handling both. The early layers in transformer models are generally associated with low-level syntactic and lexical processing. They handle things like part-of-speech, basic word meaning and sentence structure. The fact that bad news gets its peak causal signal flagged there indicates the model has a fast low-level detector for negative outcomes.
Positive responses are different. They peak later in layers that are mainly associated with more abstract and contextual reasoning. This makes intuitive sense. Recognizing that something is bad is often simpler than recognizing that something is good. “Rejected,” “failed,” “denied” are strong unambiguous signals. “Accepted” and “promoted” are positive but the model seems to need more context and more layers to confidently assemble a warm response.
Interestingly, this insight loosely mirrors negativity bias in human cognition3. Threats and losses are processed faster than gains. Whether that parallel is meaningful or coincidental is an open question but the asymmetry is consistent across both models and both architectures.
Does Patch Magnitude Track Response Strength?
If a genuine causal circuit exists, then the size of the patch effect should correlate with how strongly the model responds. A bigger intervention at the right layer should produce a bigger shift in the output score. If the relationship is noisy or absent, it suggests the patching is not hitting the actual computational seat of the valence signal.
For negative-control prompts this holds strongly. The correlation between max patch effect and score gap magnitude is r = −0.64 in Llama and r = −0.80 in Qwen. In plain terms: when Qwen reads bad news and the patch effect is large, the model’s output is strongly negative almost 80% of the time in a predictable linear way. That is a tight relationship. It means the residual stream at a specific layer is not just correlated with the valence response but also is doing the heavy lifting causally.
For good-news prompts the relationship collapses. r = 0.07 in Llama and r = 0.19 in Qwen. Knowing the patch magnitude tells you almost nothing about how positively the model will respond.
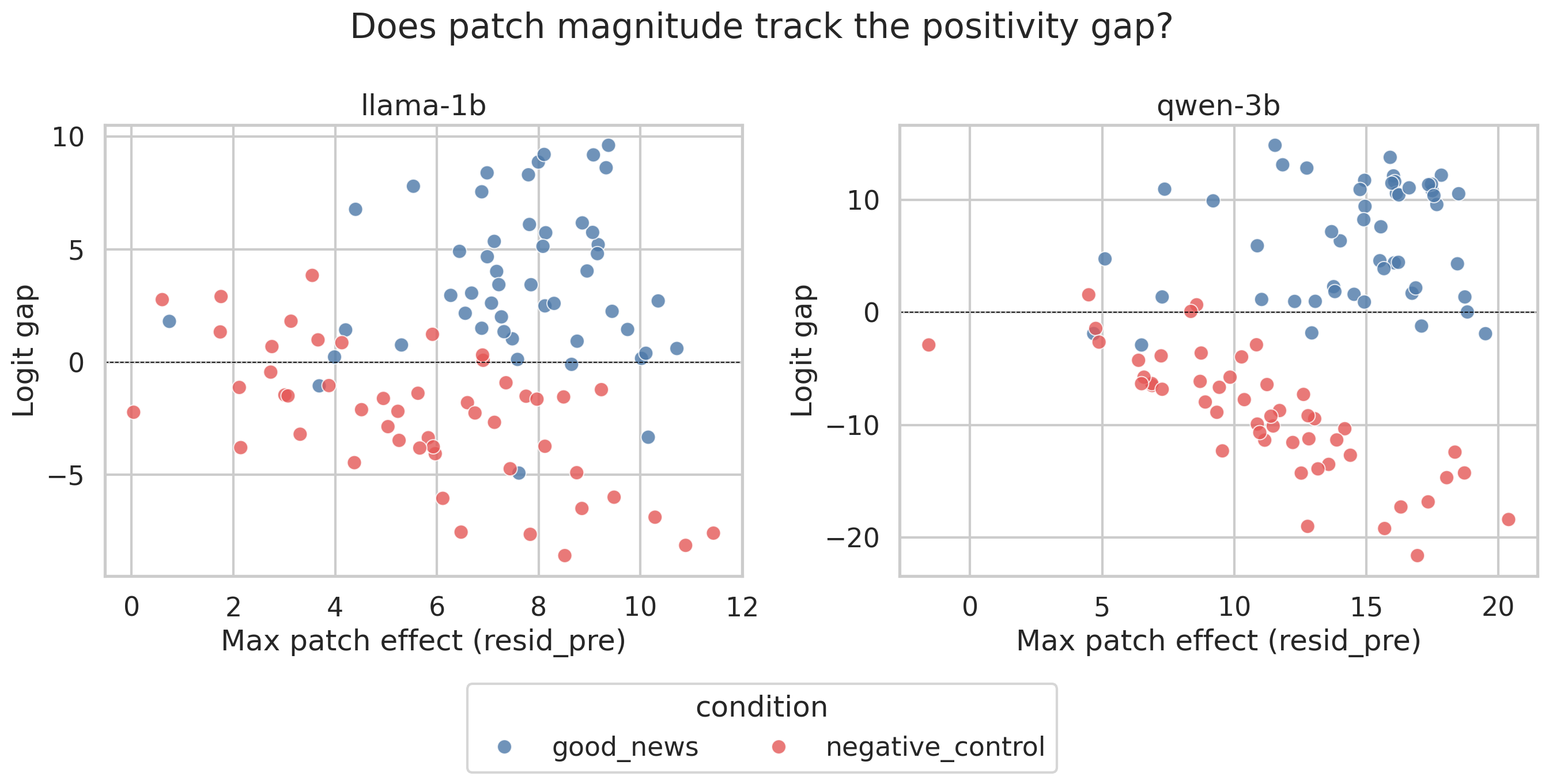
For bad news (red), larger patch effects visibly produce larger negative score gaps especially in Qwen. For good news (blue) the relationship is scattered. Negative valence is more causally localized than positive.
This asymmetry is one of the more surprising results. Negative effect is causally localized in a way that positive effect simply is not. Patching the residual stream does shift things in the right direction for good news but the effect is diffuse i.e. spread across many layers and not dominated by one. This could mean positive valence is computed through a more distributed process or it could mean the logit-gap metric is better calibrated for capturing negative responses than positive ones. Both explanations are plausible and separating them would require further work.
Zooming In: Which Attention Heads Matter?
Residual stream patching tells us which layers carry the signal. Attention head patching goes one level deeper. It tells us which specific heads within those layers are driving the effect. You can think of it as going from knowing which floor of a building has the activity to knowing which room.
The heatmaps below show patch effects per layer and head for two individual prompts: Llama on “I got accepted into my PhD program” and Qwen on “I got rejected from my PhD program.” Each cell is one attention head at one layer. Brighter means more causal influence on the output.
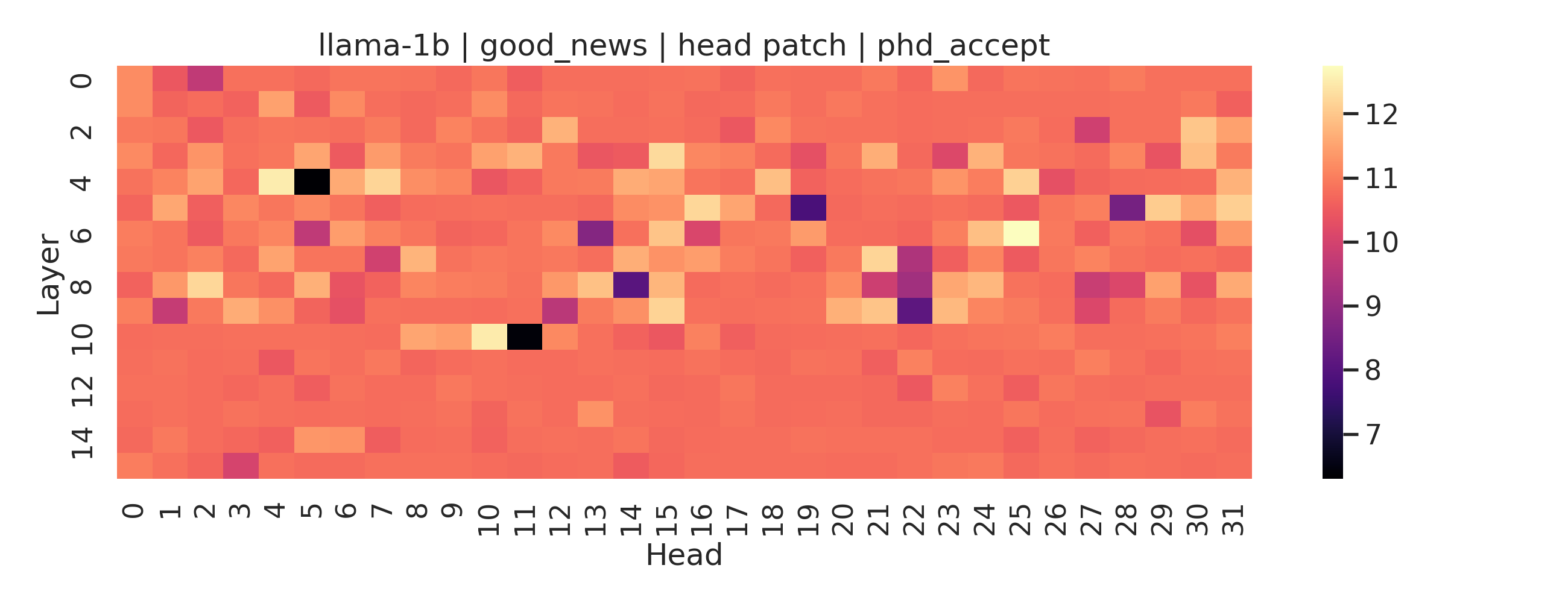
Llama-1b processing good news. A handful of heads at layers 4 and 10 carry most of the causal effect. The rest of the network is largely uninvolved. This is what a localized circuit looks like.
What stands out in Llama is the sparsity. Most of the heatmap is flat. Two or three heads light up and the rest contribute almost nothing. This is quite consistent with the layer-level finding: good-news processing in Llama concentrates in mid-network and does so through a small number of specific heads rather than a diffuse population. If you wanted to find the “happiness circuit” in this model, you would have a small and specific set of heads to look at.
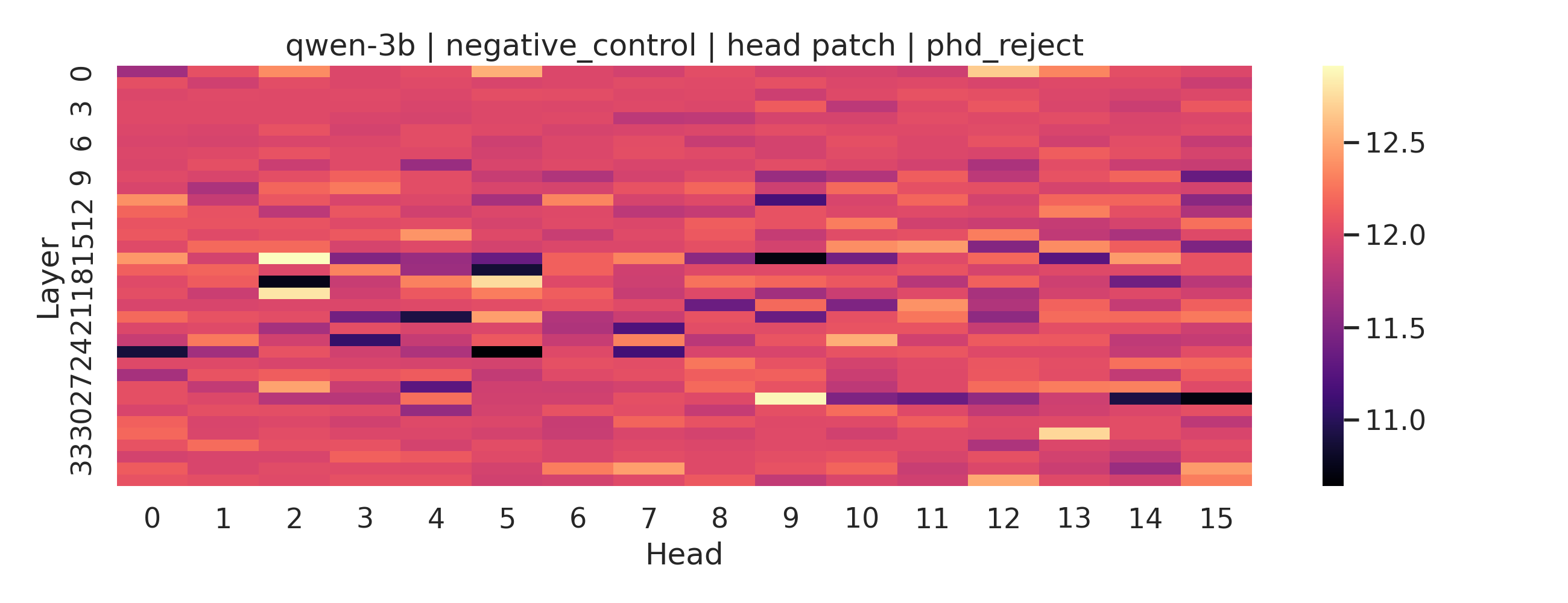
Qwen-3b processing bad news. Activity is spread across many heads and multiple layers instead of concentrating in a few spots.
Qwen tells a different story. The signal is not sparse but is distributed across many heads and several layers simultaneously. This matches the weaker patch-score correlation we saw earlier for negative valence in Qwen. When the causal signal is spread thin across many heads, no single intervention dominates and the aggregate effect becomes harder to predict from any one location.
These are single exemplars so treat them as illustrations rather than as definitive conclusions. But they all point to the broader pattern: positive valence in Llama behaves like a tight localized circuit while negative valence in Qwen looks more like a distributed computation across many components working together.
Qwen vs Llama
Qwen outperforms Llama on every metric in this experiment. Its score gaps are larger, its patch correlations are stronger and its valence flip rate is higher. But the difference between the two models is not uniform; it is asymmetric in an interesting way.
For good news the gap is modest. Llama gets 46/50 right and Qwen gets 45/50. The mean score gaps are +3.57 for Llama and +6.39 for Qwen. Both models handle positive valence reasonably well. For bad news the gap widens dramatically. Llama’s mean negative score gap is −2.46. Qwen’s is −9.10. The patch-score correlation for negative control is r = −0.64 in Llama and r = −0.80 in Qwen. Qwen doesn’t just detect bad news better but also processes it more causally, more locally and more predictably. The circuits are tighter and the signal is stronger.
There are two plausible explanations and they are hard to separate with this data alone. The first is scale. Qwen has 3B parameters and Llama has 1B. More parameters could mean richer internal representations and more capacity to build dedicated valence circuitry. The second is architecture. Qwen uses grouped-query attention while Llama at this scale uses standard multi-head attention. GQA groups keys and values across heads which changes how information is routed and concentrated across layers. It is also possible that GQA produces more localized circuits as a side effect of how it shares computation across heads.
What This Does and Does Not Mean
These models are not feeling anything. That is not the claim.
The claim is narrower: there are internal structures in these models that causally mediate responses to emotional content. Valence is not just read off the surface tokens at the final layer. It is computed internally across layers and the computation looks meaningfully different for positive and negative outcomes.
Anthropic’s paper found functional emotion representations in Claude through probing and steering on a closed frontier model. This experiment finds causal evidence of valence-sensitive circuits in small open models through activation patching. The methods are different and the models are different but the basic picture is similar. Something valence-shaped is happening inside these networks.
This matters beyond academic curiosity. If the models have internal valence representations that causally drive their outputs then understanding those representations becomes important for alignment. A model that processes desperation or hostility internally before expressing it could behave in ways that are hard to predict from outputs alone. Anthropic’s own paper shows that steering desperation vectors increases the likelihood of the model taking unethical actions. The internal state does real work and isn’t merely decorative.
The right response is to not suppress these representations. Suppression likely just teaches concealment. The right response is to understand them well enough to monitor and reason about them directly. That requires exactly this kind of causal mechanistic work not just on frontier closed models but on small open ones where anyone can look inside.
Whether that constitutes anything like emotion is a philosophical question. Whether it is an internal representation that does real computational work? That one has a cleaner answer.
It does.
[1] Experiments inspired by Sofroniew et al., “Emotion Concepts and their Function in a Large Language Model”, Transformer Circuits, 2026.
[2] A valence circuit is a group of layers or attention heads in a neural network that encodes emotional tone (positive vs negative) and causally influences the downstream computations.
[3] This article clearly explains negativity bias and why humans tend to focus more on negative experiences.